在当下的时代,'脚本语言/编程语言'数不胜数,很多人都认为自己学习编译原理是闭门造车,不应该去浪费时间学这个,却不知学习编译原理可以更好的理解编译器的运行过程。
就比如f1比赛,其实现在所有的车队可选的轮胎都是一样的,但不同车队根据自己车的情况和战术等做出的选择就会截然不同。如果你对轮胎的理解只是它可以转,那么你根本无法把它的能力发挥到极限。
下面这段我是在知乎找到的:
你现在觉得枯燥,我想既跟编译原理本身比较抽象的知识有关,也跟讲述者有关。一个好的讲述者会试着化抽象为形象,以丰富生动的例子来为你解释。而编译原理是否有用?我认为这门课是一门真正与代码做斗争的课程,对于一个有至于追求技术的人是不容错过的课程,而且编译原理可以说是一个计算机科学的缩影。你学习它更多的是去追寻程序设计语言的本质,如它在寄存器分配中将会使用到贪心算法,死代码消除中将会使用到图论算法,数据流分析中使用到的Fixed-Point Algorithm,词法分析与语法分析中使用到有限状态机与递归下降这样的重要思想等等,也许你以后不会成为一个编译器开发工作者,但是编译原理的学习中所获,所思的东西足以让你终生获益。同时,学完这门课程,对于一个有Geek精神的开发者,他会开始运用自己的所学开发享受“上帝”的感觉,去尝试创造一门语言,我想这种感觉不是每门课程都能带给你的。我相信,当你真正完成这个过程后,你对你所写的程序、程序语言都会有更深的本质认识,这样的认识也会让你站的高度完全不同,如果你真的学的好,我想别人看到的是语法,你看到的是背后的实现,这样的感觉真的很好的,不信你试试。有了这么多好处,无论如何都有足够的理由支撑你好好学习了。
本人也只是个渣渣,大神勿喷
好了,废话不多说了,上代码:
//引入头文件
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
#include <string.h>
#include <stdbool.h>
#include <conio.h>
//variable在英语中是变量的意思
//定义结构体variable
struct variable{
//计数变量
signed int i;
//字符串长度变量
signed int Len;
//技术变量
signed int j;
//寄存器下标
signed int r;
//字符串接收变量
char*String;
//字符变量
char Char[10];
//接收数字字符串变量
char*str;
//判断条件的数组
bool boolean[10];
}Nect;
//Nect.boolean = false;
//Nect.cty = false;
//character在英语中是字符的意思
//字符分割函数,i是寄存器
void Token(char character,int i){
switch(character){
//如果为+则字符的ascll码+1
case '+':
Nect.Char[i]++;
break;
//如果为-则字符的ascll码-1
case '-':
Nect.Char[i]--;
break;
//打印字符
case 'P':
putchar(Nect.Char[i]);
break;
//接受一个用户输入字符
case 'I':
Nect.Char[i] = getchar();
break;
//如果都没有则直接退出,如果不这么做则会返回字符
default:
return;
break;
}
return;
}
//清空指针
char*NullChar(char*Cha,int j){
int i = 0;
for(i = 0;i < j;i++){
Cha[i] = 0;
}
return Cha;
}
//检查字符是否为数字字符
char Ichar(char ch){
switch(ch){
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
case '-':
break;
default:
return '0';
break;
}
return ch;
}
//将字符转转换函数
int Int(int b){
switch((char)b){
case '1':
b = 1;
break;
case '2':
b = 2;
break;
case '3':
b = 3;
break;
case '4':
b = 4;
break;
case '5':
b = 5;
break;
case '6':
b = 6;
break;
case '7':
b = 7;
break;
case '8':
b = 8;
break;
case '9':
b = 9;
break;
default:
b = 0;
break;
}
return b;
}
//代码执行函数
int user(char token[99999]){
//定义一个结构体指针并分配内存
struct variable*Next = (struct variable*)malloc(sizeof(struct variable));
//分配内存
Next -> String = (char*)malloc(sizeof(char));
Next -> str = (char*)malloc(sizeof(char));
//将获取的字符串转存入String变量
Next -> String = (char*)token;
signed int j = 0;
//获取代码的字符个数
Next -> Len = strlen(Next -> String);
//便利字符串
for(Next -> i = 0;(Next -> i) <= (Next -> Len);Next -> i++){
//如果有'+['则后面的数字都为要增加的ascll码
//不超过十,如果比如要给字符增加11,需要这样:+[11]
switch(Next -> String[Next -> i]){
case 'I':
Next -> r = Int(Next -> String[Next -> i+1]);
break;
case 'R':
if((Next -> String[Next -> i+2]) == '='){
Nect.Char[Int(Next -> String[Next -> i+1])] = (Next -> String[Next -> i+3]);
Next -> i += 4;
}
break;
case '+':
if((Next -> String[Next -> i+1]) == '['){
//当前遍历的字符位置+1
Next -> i+= 3;
//boolean[0]为true
Nect.boolean[0] = true;
Next -> r = Int(Next -> String[Next -> i-1]);
}
break;
//类似上面的if,只不过这个是-字符的ascll码
case '-':
if((Next -> String[Next -> i+1]) == '['){
Next -> i += 3;
Nect.boolean[1] = true;
//获取寄存器下标,如果不是数字则默认为0,如:+[0 123456]
//ps:可以不空格
Next -> r = Int(Next -> String[Next -> i-1]);
//如果为]则数组boolean全部为false
}
break;
case ']':
if(Nect.boolean[0] == true){
Nect.Char[Next -> r] += atol(Next -> str);
Nect.boolean[0] = false;
}else if(Nect.boolean[1] == true){
Nect.Char[Next -> r] -= atol(Next -> str);
Nect.boolean[1] = false;
}
j = 0;
NullChar(Next -> str , 10);
/*
Next -> str[0] = 0;
Next -> str[1] = 0;
Next -> str[2] = 0;
Next -> str[3] = 0;
Next -> str[4] = 0;
*/
break;
case 'P':
//获取要打印的寄存器下标,如:P1
Next -> r = Int(Next -> String[Next -> i+1]);
break;
case 'n':
//清空指定寄存器,如:n0
Nect.Char[Int(Next -> String[Next -> i+1])] = 0;
break;
//所有寄存器变量的内容全部清空
case 'N':
for(j = 0;j < 10;j++){
Nect.Char[j] = 0;
}
break;
}
if(Nect.boolean[1] == true || Nect.boolean[0] == true){
//Nect.Char[Next -> r] -= Int(Next -> String[Next -> i]);
Next -> str[j++] = Ichar(Next -> String[Next -> i]);
//否则就把字符的ascll码加上括号内的数
}else{
Token(Next -> String[Next -> i],
Next -> r);
}
}
//释放指针
free(Nect.String);
free(Nect.str);
//释放结构体指针
free(Next);
return 0;
}
//主体部分
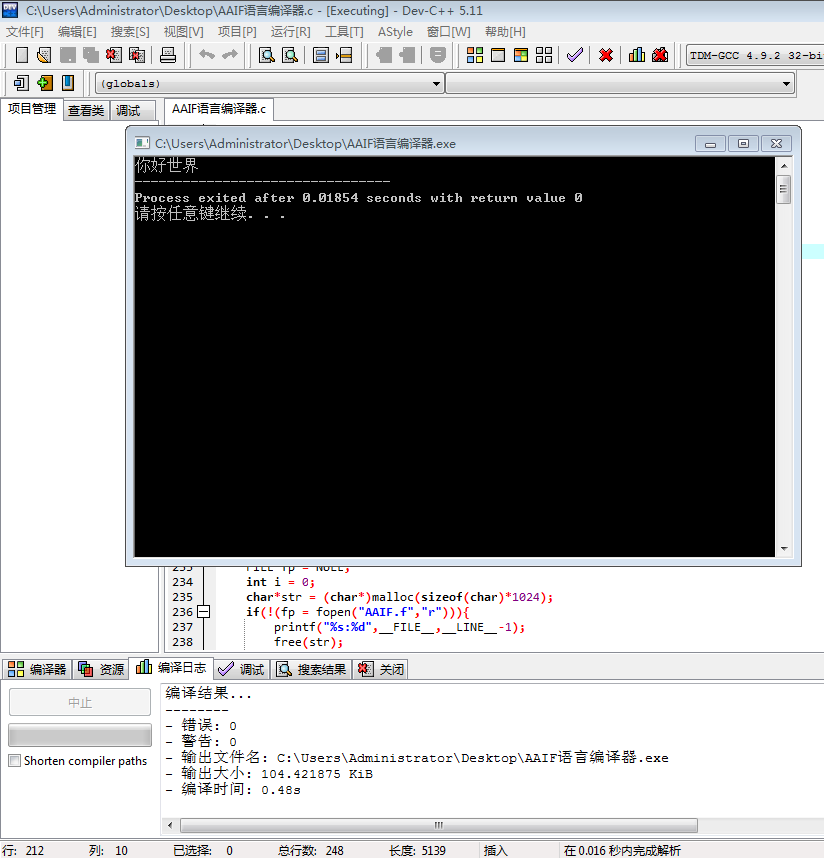
int main(int argc, char** argv) {
FILE*fp = NULL;
int i = 0;
char*str = (char*)malloc(sizeof(char)*1024);
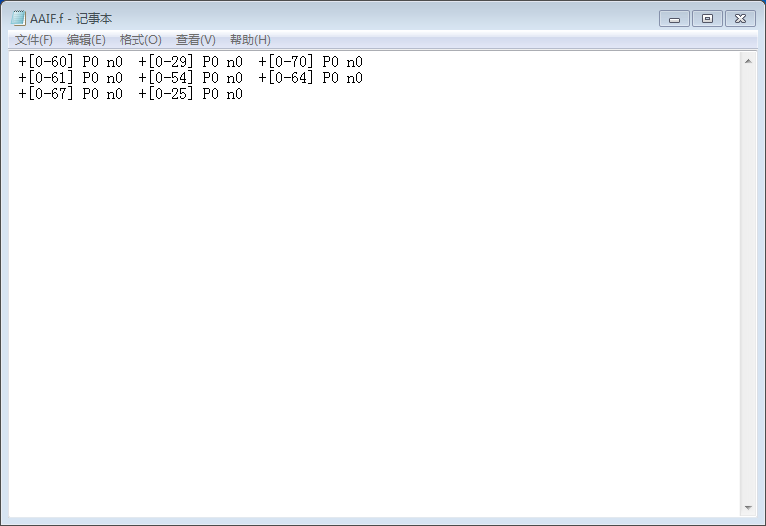
if(!(fp = fopen("AAIF.f","r"))){
printf("%s:%d",__FILE__,__LINE__-1);
free(str);
exit(0);
}
for(i = 0;!(feof(fp));i++)
fscanf(fp,"%c",&str[i]);
//这里是要执行的代码
user(str);
fclose(fp);
free(str);
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
#include <string.h>
int main(){
FILE*fp = NULL;
if(!(fp = fopen("AAIF.f","w"))){
fprintf(stderr,"写入文件出现错误");
exit(0);
}
char*String = (char*)malloc(sizeof(char));
//
String = "你好世界";
int Len = strlen(String);
int i = 0;
for(i = 0;i < Len;i++){
if((i % 3) == 0 && i >0){
putchar('\n');
fputc('\n',fp);
}
printf(" +[0%d] P0 n0 ",String[i]);
fprintf(fp," +[0%d] P0 n0 ",String[i]);
}
fclose(fp);
}会在当前目录生成AAIF.f文件,'你好世界'那里则是要转换的文字